
Empezamos aplicando el algoritmo a la ecuación del calor en una dimensión:

Con difusividad térmica 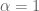

o, más en concreto:

Para empezar, 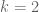

Paso 1:
Paso 2:
Paso 3:
Paso 4:
Paso 5:
Soluciones invariantes:
Paso 1: Aplicar el generador infinitesimal extendido a la EDP según lo establecido en el teorema del post anterior: 
Paso 2: Derivar los infinitesimales extendidos necesarios, dados por las ecuaciones (3.59), utilizando la derivada total, D_i, definida en (3.60).
Paso 3: Insertar los infinitesimales extendidos en el resultado obtenido en el Paso 1 y agrupar los infinitesimales según las variables dependientes y sus derivadas. La condición F=0 debería ser introducida en este paso.
Paso 4: Resolver el sistema de ecuaciones diferenciales obtenidas al igualar cada corchete a 0.
Paso 5: Formular el generador infinitesimal multiparamétrico de todas las simetrías y dividirlas en simetrías de Lie uniparamétricas.
Soluciones invariantes: una vez que se han obtenido las simetrías de Lie uniparamétricas, el último paso consiste en obtener soluciones invariantes del sistema de EDPs utilizando las simetrías obtenidas. En el campo de la dinámica de fluidos, estas soluciones invariantes son conocidas como leyes de escala.

El grupo de Lie uniparamétrico de transformaciones


deja invariante un sistema de PDEs 




deja invariante las 

El correspondiente generador de la extensión infinitesimal k-ésima del grupo de Lie de transformaciones (compuesto por 


Las derivadas de variables dependientes que aparecen en las ecuaciones diferenciales se consideran como variables dependientes extra y su transformación debe tenerse en cuenta y pueden ser calculadas mediante la regla de la cadena.
Las transformaciones que teniamos eran:


Las transformaciones extendidas son:
donde las funciones 


para 

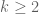


Tenemos ahora
donde 


Sean 



Entonces, las
con 



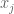

Y también la notación para derivadas superiores:

con 


En el último post antes del verano, hablamos de la generalización de grupos de Lie actuando no solo sobre una PDE sino sobre un sistema de PDEs y enumeramos algunas de las generalizaciones que debíamos hacer. En estos próximos post trataremos de abordar cada una de las generalizaciones enumeradas.
La idea de función invariante introducida en el post anterior puede generalizarse a sistemas de ecuaciones en derivadas parciales.
Primero que nada, habrá que definir la notación que utilizaremos.
Lo primero generalizable será el concepto de grupo de Lie de transformaciones actuando sobre un sistema de PDEs.
A continuación, podremos definir el generador infinitesimal.
En la búsqueda de simetrías de Lie, hay que tener en cuenta que las derivadas de las variables dependientes que aparecen en las ecuaciones diferenciales se considerarán como variables dependientes extra.
Hablaremos de transformaciones extendidas cuando tratamos con las transformaciones de las derivadas de las variables dependientes.
Dada una función 


Existen un teorema al respecto que nos dice que 

Por ejemplo, dada la función 




con 

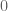



y con 
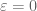
Por el post anterior, podemos identificar al grupo de Lie 


donde 


Aplicamos al grupo traslacion…
El operador

donde 

Dada una función diferenciable 


Para el caso particular de 

Dado el grupo de Lie uniparamétrico de transformaciones 

con 

En particular,

donde

Como ejemplo, imaginemos el grupo de translaciones en el eje de las


donde la ley de composición 





Llegados a este punto, dado el problema de valor inicial


con 

es solución del mismo.
Dado un grupo de Lie uniparamétrico de transformaciones 
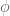
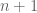

Si definimos:

como el infinitesimal del grupo de Lie uniparamétrico, podemos definir la transfomación infinitesimal como

La idea que hay detrás de los grupos infinitesimales, parece que originalmente atribuible a Lie, es que, hablando en un caso particular, rotar 
![\pmb{R}(\alpha) = [ \pmb{R}(\frac{\alpha}{N})]^N](https://s0.wp.com/latex.php?latex=%5Cpmb%7BR%7D%28%5Calpha%29+%3D++%5B+%5Cpmb%7BR%7D%28%5Cfrac%7B%5Calpha%7D%7BN%7D%29%5D%5EN+&bg=ffffff&fg=545454&s=0&c=20201002)
Una simetría de Lie o transformación de Lie es un grupo (matemáticamente hablando) de transformaciones con algunas propiedades.
Un grupo 



Dado un 

definido para cada 











Además, tendremos un grupo de Lie uniparamétrico de transformaciones si a) 
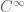
Ejemplos en el plano, para entender la nomenclatura, podrian ser 1) rotación de angulo 





Por una parte, es difícil resolver (sistemas de) ecuaciones en derivadas parciales (EDPs). Por otra, aparecen en multitud de problemas físico-matemáticos, pues son una de las herramientas más potentes a la hora de modelar sistemas.
Una de las aproximaciones seguidas en todos los trabajos realizados hasta el momento a lo largo de este blog es la utilización de los métodos numéricos para la obtención de soluciones.
Vamos a dedicar unas cuantas entradas a trabajar sobre un método general de integración, las simetrías de Lie que, por un lado, son una generalización de muchos métodos particulares conocidos hasta el momento de su introducción y, por otro, está basado en la invariancia de estos sistemas de EDPs bajo un grupo continuo de simetrías.
El método trata de encontrar las simetrías de una EDP calculando el grupo uniparamétrico de transformaciones que la dejan invariante, convirtiendo el conjunto de soluciones en soluciones.
Para ejemplificar esta técnica, encontraremos las simetrias de dos ecuaciones unidimensionales: la ecuación del calor 

Sabemos que, de forma general,

y


Recordemos que, bajo ciertas condiciones de continuidad y diferenciabilidad, existe commutatividad en las derivadas de orden superior, es decir:

donde 
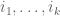

Así pues, en realidad, tenemos:

y

Retomo el blog despues de mucho tiempo inactivo. Empecé con astrofísica y relatividad numérica, dediqué unas pocas entradas a programación básica y ahora lo retomo en una área muy de moda y en la que me encuentro trabajando: Machine Learning.
La última construcción iterativa es el para , que se utiliza cuando sabemos, a priori, el número de iteraciones que vamos a realizar
La sintaxis en C++ es:
para @ hasta hacer
En C++ tenemos:
for ( contador = valor_inicial; condicion;
Un sistema es autónomo cuando la variable 


El espacio de fases es el conjunto de todas las posibles configuraciones de un sistema. Si el sistema depende de un número
Si estudiando un gas de 
Si el sistema es autonomo, cada punto del espacio de fases siempre tiene el mismo vector de velocidad asociado.
Para autovalores reales, cada autovector correspondiente define una recta invariante en el espacio de fases que pasan por el punto de equilibrio, siendo estos aquellos puntos donde se anula la derivada. Si el autovalor es positivo, el punto de equilibrio es repulsivo, mientras que si es negativo entonces es atractivo.
Para autovalores puramente imaginarios, tenemos círculos alrededor de los puntos de equilibrio, mientras que si son complejos, en función de si la parte real es positiva o negativa, tendremos espirales que escapan del punto de equilibrio o que se acercan a el respectivamente.
Para los sistemas no lineales, linealizamos alrededor de los puntos de equilibrio mediante el jacobiano.
composicion iterativa
mientras
repetir
composicion secuencial
composicion alternativa
alternativa simple
alternativa doble
alternativa multiple
Los lenguajes de programación nos van a permitir escribir programas, es decir, escribir algoritmos en un lenguaje capaz de ser procesado por un computador.
Los lenguajes de programación son lenguajes y, por lo tanto, constan de un léxico, una sintaxis y una semántica.
El léxico es el conjunto de palabras que forman el lenguaje (en C++, por ejemplo, tenemos if, else, +, -, 2, 7.89, etc). La sintaxis es el conjunto de reglas que nos indican como construir frases (C++: if (i>0) { i--;}). La semántica es lo que dota de significado a cada una de esas frases.
Podemos clasificar los lenguajes de programación de diferentes maneras.
En función de su proximidad a la computadora, su arquitectura, o al programador, tenemos lenguajes de bajo nivel y lenguajes de alto nivel.
Los lenguajes de bajo nivel son muy cercanos a la arquitectura del computador (su juego de instrucciones) lo que los hace muy difíciles de programar a la vez que poco portables. Dos ejemplos son el lenguaje máquina (es en binario) y el ensamblador (se utilizan mnemotécnicos en lugar de secuencias de ceros y unos).
Los lenguajes de alto nivel son independientes de la arquitectura (basados en máquinas abstractas) y son mucho más próximos (en cuanto a léxico, sintaxis y semántica) a las personas. Todo esto los hace mas sencillos, flexibles y potentes. Sin embargo, como el computador no los entiende directamente, necesitamos de un traductor (interprete o compilador).
En función del paradigma, la filosofía que hay detrás, tenemos lenguajes de programación procedurales y lenguajes de programación declarativos. En los primeros se describe la secuencia de pasos para resolver el problema (COMO) mientras que en los segundos simplemente se describen los mismos (QUE). Para los primeros tenemos lenguajes imperativos (prima el procedimiento) y lenguajes orientados a objetos (prima el dato). Para los segundos tenemos los funcionales (funciones matemáticas) y los lógicos (predicados lógicos).
Finalmente, en función de si se traducen todas las sentencias de golpe para su posterior ejecución, compilados, o si se va traduciendo y ejecutando instrucción a instrucción, interpretados.
¿Qué elementos forman el léxico de un lenguaje? En primer lugar, las palabras reservadas: tienen un significado especial dentro del lenguaje, son sus instrucciones más básicas, y no se pueden utilizar para nada mas (listas para C#, C++ y Java). En segundo lugar, los símbolos, que pueden ser operadores (C++: =, +, -, …), delimitadores (C++: [, ], (, ), {,…), comentarios (C++: /* */, //) o directivas de preprocesado, que son ordenes especiales para el compilador (C++: #). En tercer lugar, los identificadores, que nos permiten dar nombres a constantes, variables y procedimientos (en C++ aparecen caracteres alfanuméricos, es decir, letras y números junto con el símbolo _. Han de empezar por una letra o por _ y se distinguen las mayúsculas de las minúsculas). Finalmente, tenemos los valores constantes: numéricos (3.56), carácter ('b') o cadena ("hola").
Las variables son «cajas» donde vamos a poder almacenar datos. El tipo de dato que almacenan va a ser fijo, pero el valor puede ser «variable», de aquí su nombre. Estas cajas se corresponden con zonas de memoria accesibles mediante nombre. Se identifican con un nombre y tienen cuatro atributos: su tipo, su valor, su ámbito y su tiempo de vida. Con ella podemos consultar (indirección) su valor o modificarlo (asingación). En la mayoria de lenguajes se tienen que declarar (se fija el tipo y el nombre) antes de utilizarlas (C++: float a, b=1.2, c;).
Las constantes, a diferencia de las variables, almacenan un valor de un tipo que ya no se podrá modificar (C++: const double PI = 3.141592;). Ayudan a la legibilidad del programa, a su mantenimiento…
Vamos a hablar de programación en lenguajes de alto nivel.
Para empezar, repasamos los conceptos de algoritmo y de programa.
Un algoritmo es una secuencia de pasos a seguir para resolver un problema. Es un concepto previo a la programación (algoritmo de multiplicación, algoritmo de Euclides, etc.). La secuencia tiene que ser finita, y el tiempo de ejecución (y por lo tanto, cada uno de los pasos) también. Generará una o más resultados (salidas) y necesitará ninguno o más datos (entradas) para poder generar los primeros.
Un programa es la traducción de un algoritmo a un lenguaje de programación, es decir, a un lenguaje que un ordenador «entiende».
Por ejemplo, en el caso del algoritmo de Euclides, que calcula el MCD de dos números A y B, utilizamos las propiedad 1) MCD(D,d) = MCD(d,r), donde D es el Dividendo, d es el divisor y r es el resto de la división entera entre D y d. Y que, si r=0 entonces MCD(d,r)=d. Con esto, un posible algoritmo sería:
Datos de entrada: dos enteros A y B
Datos de salida: el MCD
1.- Calcular el resto r de dividir A entre B
2.- Si la r es 0, el MCD es B y acabamos
3.- Colocamos el valor de B en A y el de r en B
4.- Volvemos a 1
Fijémonos que, la primera vez que se ejecuta el paso 1, en el caso de que B fuera mayor que A, el calculo de la división entera hace el swap entre las dos variables.
Ya veremos mas adelante que evitaremos sentencias del tipo 4 (equivalentes al GOTO) simplemente utilizando un bucle.
Con respecto a las fases de creación de programas, hemos visto el modelo en cascada, utilizado en ingeniería del software. La fase de análisis contesta a la pregunta de que debe hacer mi programa, la de diseño a como debo hacerlo (describir el algoritmo) y la implementación no es mas que la traducción de nuestro algoritmo a un programa. La fase de validación consiste en eliminar errores (que pueden ser léxicos, sintácticos o semánticos y que nos harán volver a alguna de las fases anteriores).
Para terminar, y con respecto a la representación de algoritmos (necesaria en el diseño de los mismos) utilizaremos pseudocódigo, aunque también podríamos hacerlo mediante el uso de diagramas de flujo u organigramas. Al final necesitamos una representación (textual o gráfica) de las estructuras secuencial, alternativa e iterativa junto con las operaciones de entrada/salida de los datos.
Un ordenador o computador es una máquina (electrónica) de propósito general: sirve para muchas cosas en función del programa que ejecute. Ordenador viene de ordenar, y computador viene de computar. Básicamente, lo que queremos es resolver problemas.
Un algoritmo es una secuencia ordenada de pasos. La idea existe de mucho antes que los ordenadores: algoritmo de Euclides (como calcular el MCD de dos números, propuesto a.C.), la formula de la ecuación de segundo grado es un algoritmo. Pero una receta de cocina también es un algoritmo.
Un programa es la codificación de un algoritmo de manera que pueda ser llevado a cabo por un ordenador. Se debe escribir en un lenguaje que un ordenador entienda. Los lenguajes de programación son «idiomas» que entiende un ordenador. Como cualquier otro lenguaje, tienen un léxico (palabras del lenguaje), tienen una sintaxis (reglas para construir frases) y poseen una semántica.
Todos los ordenadores actuales están basados en la máquina de Von Neumann: Hay una Unidad Central de Proceso (CPU), una Memória (M) y unos dispositivos de Entrada/Salida (E/S) todos interconectados mediante un Bus. Todo esto forma el hardware (la parte tangible) del ordenador. Pero hay toda una parte no tangible, el software, necesaria para el funcionamiento de mismo: los programas de los que hablábamos.
La CPU es el «cerebro» del computador, o sea, es la que sabe hacer las cosas. Por una parte, sabe hacer cálculos (aritméticos, como sumas, restas, … y lógicos, como and, or, not, etc.), mediante la Unidad Aritmetico-Lógica (ALU), que forma parte de la Unidad de Proceso (PU). Por otra, es la que marca el ciclo de ejecución de las instrucciones, conteniendo la Unidad de Control (CU).
En la memoria es donde se almacena la información. La información fundamental que se guardan son los programas. Pero además, estos programas necesitan datos. Toda esta información está codificada.
Los dispositivos de E/S nos permiten hacer del computador un sistema abierto, ya que nos permite, por una parte, introducir nueva información al sistema, mediante los dispositivos de entrada (un teclado, un ratón, …), y por otra, que el sistema nos pueda hacer llegar la información procesada, mediante los dispositivos de salida (pantalla, …).
El bus permite el flujo de información entre los diferentes componentes.
Con respecto al software, tenemos de dos tipos: software de sistema, necesario para el funcionamiento del mismo: programa de arranque, el sistema operativo, compiladores, depuradores, herramientas de mantenimiento y diagnostico; software de usuario, cualquier programa/aplicación útil para resolver un problema determinado: editor de textos, gestor de bases de datos, navegador, hoja de calculo, herramientas CAD/CAM, etc.
